If you want to know how to build a sanely-architected url-shortener using AWS Lambda on top of a datastore like Postgres, this is not the post for you. We’re going to build a Rube-Goldberg url-shortener using just Lambda.
And since it may not be clear to everyone, this post contains Bad Ideas™ and Extremely Inappropriate Uses of Tools®. Don’t try this in production.
Lambda
As a brief background, AWS Lambda is a “Function as a Service” service. You give amazon some code (a function) and they’ll run it for you — once, 1000 times, 1000 times at once, whatever you need. It’s a way of running certain kinds of code in the cloud without needing to manage your own server, not even a virtual one.
Lambda is a very specific kind of hammer that’s extremely good at hammering a very specific kind of nail. This blog post will not be discussing that nail. This blog post will not discuss anything close. Because it turns out you can use a hammer to drive a wing-nut into silly putty if you swing hard enough and are willing to get messy.
Read
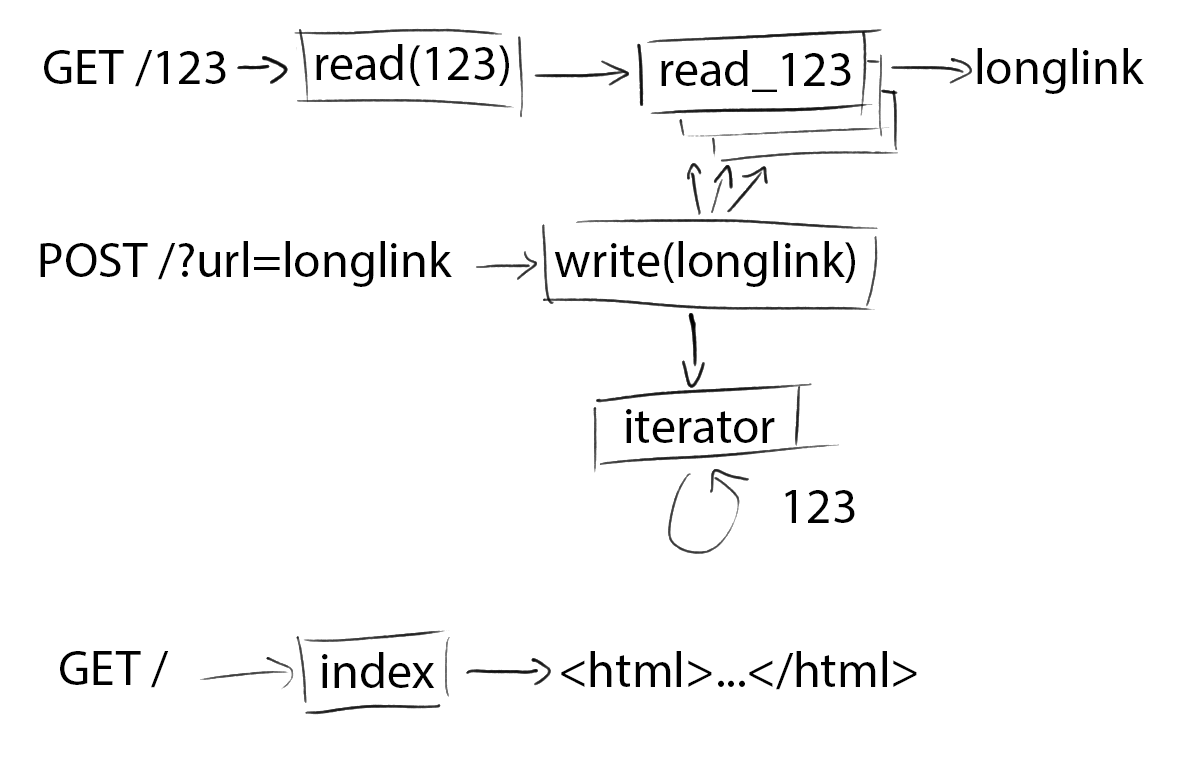
Ok, so the first thing any url-shortener needs is link mapping. Somewhere you need to store that /123 maps to html5zombo.com. Well, you’ve got an input and an output - that sounds like a Lambda function! What if we just create a new Lambda function for every link mapping! Millions of separate Lambda functions. After a quick check to make sure there’s no limit on the number of Lambda functions you can have (besides an upper limit of 75GB of storage space), we’re off to the races.
As an example, the function read_123 will just be hardcoded to return html5zombo.com:
def handle(event, context):
return { 'url': 'html5zombo.com' }
However, a url-shortener needs to produce links, not Lambda functions. We want the url /123 to trigger this function and return the url as a 301 redirect. For that we turn to API Gateway. It’s a poweful, flexible tool with a million options, but we’re just going to use it to hot-glue urls to lambda functions. For our read function, we can configure a resource (123) and a method on that resource (GET) to trigger our Lambda function.
Unfortunately, Api Gateway wasn’t built to support thousands and thousands of separate endpoints like /123, /124, /125, etc. There’s a limit of 300 resources per api. You can request an increase on that limit, but I suspect “because I thought it would be funny” won’t be a compelling justification.
We’re not stuck, though—we can fix this problem the way we fix all problems: more Lambda functions! We’ll just define one new endpoint that takes a url parameter: /{id} in api gateway. That’ll execute a single Lambda function (call it read(id)) that will, in turn, execute the specific read function (eg read_123) we want.
In pseudocode, read(123) would look like:
def handle(event, context):
read_result = AWS.lambda.invoke('read_' + event.id)
return {
'statusCode': 301,
'headers': { 'Location': read_result['url'] }
}
Alright, so using two different types of read functions, read(id) and read_123 (and _124, etc), we’ve got shortened links working. Loading up /123 in your browser tells ApiGateway to run read(123), which runs read_123, which returns html5zombo.com.
Iterator
Soon we’ll want to put together a function to generate these short links. There’s another hurdle first, though. We need a global counter! When a user goes to shorten a new link, we need to know what the next id (eg 124) is. We need to store a global counter somewhere.
Now, saner developers might tell you that Lambda is stateless and you can’t use it to store data. You and I know those people just lack strength of character. Remember: if Lambda functions don’t solve your problem, you’re not using enough of them.
As it turns out, all you need to do to store a global counter is write a self-updating Lambda function! Let’s call this function iterator, and in pseudocode it looks like:
def handle(event, context):
i = 0
myCode = load the code for this function from the filesystem
myCode = myCode.replace('i = ' + i, 'i = ' + (i+1))
AWS.lambda.updateCode('iterator', myCode)
return i
Self-updating code: what could go wrong?

Now, the observant among you might be noticing a problem (besides the obvious one that this is all horrifying): concurrent requests to this function might overwrite each other. A good fix for this would be to use literally anything else in technology as a datastore. But since obviously that’s not the fix we’re going to use, we’ll just tell Lambda to limit the maximum concurrency on this function to 1 so it can never run twice in a row!
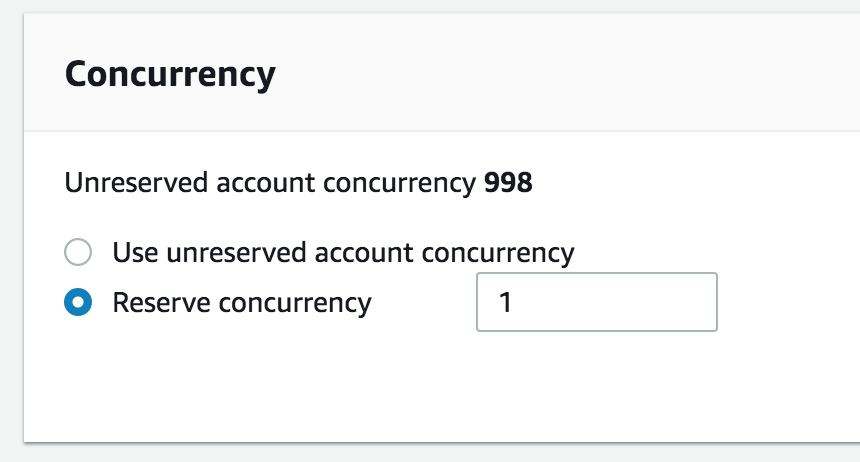
And now we’ve got our massively overcomplicated way of storing one number in the cloud! Here I am using apex, a handy Lambda cli tool, to run the iterator function repeatedly.
$ apex invoke iterator -a '$LATEST'
{"statusCode": 200, "body": "74"}
$ apex invoke iterator -a '$LATEST'
{"statusCode": 200, "body": "75"}
$ apex invoke iterator -a '$LATEST'
{"statusCode": 200, "body": "76"}
Write
Alright, we now have everything we need to create a write function - the one that actually shortens links for us. We want to be able to send an HTTP POST request with a body like { url: 'hamsterdance.com' } and receive a shortened url like kmk.party/123 in return. In yet more pseudocode:
def handle(event, context):
# Grab the url we're given
url = json.parse(event.body).url
nextI = AWS.lambda.invoke('iterator')
newFunctionBody = """
def handle(event, context):
return { url: ${url} }
"""
newFunctionName = 'read_' + nextI
AWS.lambda.createFunction(newFunctionName, newFunctionBody)
return 'kmk.party/' + nextI
As you can see, every time you use this write function to create a new shortened link, we make an api call to generate an entirely new Lambda function with unique code. This is totally reasonable and not at all a ridiculous misuse of an amazing tool.
As a brief aside, I should mention that this is a horrible security hole. url is untrusted user input, but we’re just interpolating it into code and running that code. We can work around that, though, by base-64 encoding and decoding the url.
Index
All the pieces of this abomination are in place.
Now the only thing left for a proper url-shortener is a frontend! There are plenty of simple and nearly free places to host a flat file with a bit of JS to act as that frontend so obviously we’re not going to use any of those. Hosting a flat file is, though pointless and bizarre, quite easy on Lambda (pseudocode):
def handle(event, context):
return {
'statusCode': 200,
'body': file.read('./index.html'),
'headers': { 'Content-Type': 'text/html' }
}
Index.html just contains some JS to make an HTTP POST to our write function and display the resulting short link.
And there it is: a url-shortener using only Lambda. We’ve abused AWS’s api to make self-updating functions. We’ve flooded our AWS account with single-purpose functions whose output is hardcoded. We’ve used the wrongest possible tool to serve flat files, slowly. We stopped just short of a publicly-available arbitrary code execution bug on my personal AWS account. Let’s call it a day! Here it is live at kmk.party and here’s the full, non-pseudocode.
FAQ:
This is really neat Yes it is thank you
This is absolutely horrifying See previous answer
Should I use this in production? Only if you video tape it for posterity
WHY? Because someone said I couldn’t do it
How would you actually go about building a url-shortener? The inspiration for this post was one called Building a URL Shortener with Go and AWS Lambda. I got really excited in the moments between reading that title and realizing it was really building a shortener using Go and Lambda and DynamoDB. When I get overexcited, things like this happen.
Why python? I wrote half of this in node, but creating/updating Lambda functions requires creating a zip file which node doesn’t do natively. Using a node library requires a huge node_modules folder that must itself get zipped up when you’re making a self-updating function like some kind of crazy person. Switching to python, with its built-in Zipfile module, saved a lot of time and made the iterator run in under a second instead of around 5.
I very much enjoy Code That Should Not Be Then you might like Disguising Ruby as Javascript where I wield ruby metaprogramming like a hacksaw in a horror film.
I know a way to make this whole thing even more ridiculous Tweet at me (@kkuchta)! The world-fire can always use more fuel.
]]>